

CoreTechInsights
@CoreTechInsight
Followers
7
Following
2
Media
26
Statuses
172
📊 Strategic insights at the core of tech | Cloud, AI, Data | Curated for professionals, founders & digital leaders | #TechIntelligence @CoreTechInsight
Joined July 2025
5:**.🌐 **Top Cloud Providers**:. - 🚀 AWS – Market leader .- 🧩 Azure – Microsoft integration .- 🔍 GCP – Strong in data & AI .- ☁️ IBM, Oracle – Enterprise focus . Each has strengths. Multi-cloud is rising. #AWS #Azure #GCP #CloudPlatforms #CloudStrategy.
0
0
0
4:**.⚙️ **Key Characteristics** of cloud:. - On-demand self-service .- Broad network access .- Resource pooling .- Elasticity .- Measured usage . Enables rapid innovation & scaling. #CloudBenefits #ElasticComputing #CloudInfra.
1
0
0

3:**.🏗️ **Deployment Models**:. - ☁️ Public Cloud – Shared infra (AWS, GCP) .- 🏠 Private Cloud – Dedicated infra (OpenStack) .- 🌉 Hybrid Cloud – Mix of public + private .- 🔀 Multi-Cloud – Using many providers . Flexibility is key! .#PublicCloud #HybridCloud #MultiCloud.
1
0
0
2:**.🧰 **Cloud Service Models**:. - **IaaS**: Infra (VMs, storage) – e.g. AWS EC2 .- **PaaS**: Platform to build – e.g. Azure App Service .- **SaaS**: Software ready to use – e.g. Gmail, Salesforce . Choose based on control vs convenience! .#IaaS #PaaS #SaaS #CloudModels.
1
0
0
1:**.🌩️ What is **Cloud Computing**?. It's the on-demand delivery of IT resources (compute, storage, network, services) via the internet with **pay-as-you-go** pricing. No more buying physical servers! .#CloudComputing #DigitalTransformation #Cl.
1
0
0
What is Cloud Computing? A thread. ⬇️. #CloudComputing #IaaS #PaaS #SaaS #PublicCloud #HybridCloud #MultiCloud #CloudBenefits #CloudPlatforms #CloudStrategy

1
0
0
5.Think of Data Mesh as treating data like APIs. Each domain provides clean, well-documented, and discoverable data to others — like products. Decentralized doesn’t mean chaos — it means ownership with standards. #DataStrategy #DataDriven #NextGenDataPlatform.
0
0
0
4.Why adopt Data Mesh?.✔️ Avoid bottlenecks from central data teams.✔️ Enable faster insights.✔️ Improve data quality and accountability.✔️ Scale with organization growth. #DataDemocratization #DecentralizedData #AgileData.
1
0
0
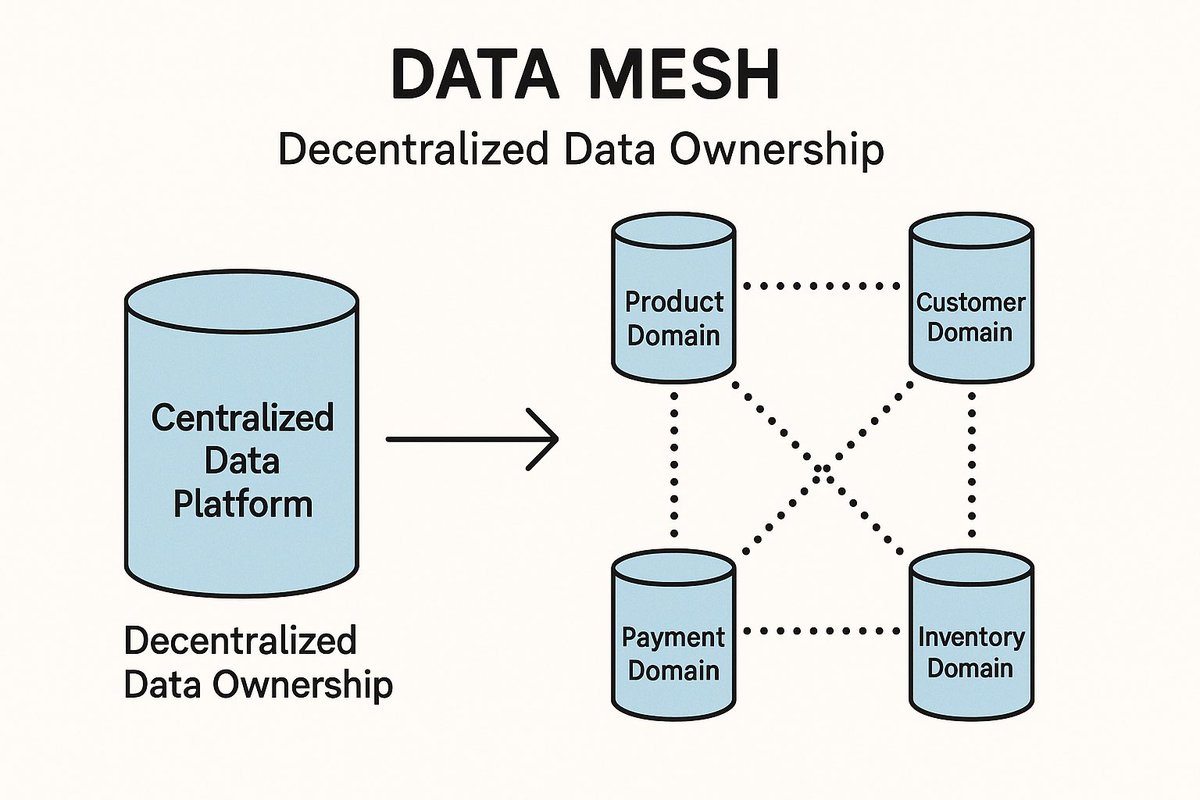
3.Key principles of Data Mesh:.✅ Domain-oriented ownership.✅ Data as a product.✅ Self-serve data infrastructure.✅ Federated governance. This enables scalability, agility, and better data quality. #DataGovernance #DataArchitecture #ScalableData.
1
0
0
2.Instead of funneling all data to a central team, Data Mesh distributes responsibilities to cross-functional domain teams. Each team owns the lifecycle of their data — ingestion, quality, transformation, and sharing. #DomainDrivenDesign #DataProduct #DataOps.
1
0
0
1.Data Mesh is a modern approach to data architecture that shifts from centralized data lakes to domain-oriented data ownership. It treats data as a product and empowers domain teams to manage and share their own data. #DataMesh #DataOwnership #ModernData.
1
0
0
Understanding Data Mesh. ⬇️. #DataMesh #DataOwnership #DomainDrivenDesign #DataProduct #DataOps #DataGovernance #DataArchitecture #ScalableData #DataDemocratization #AgileData #DataStrategy #DataDriven #NextGenDataPlatform
1
0
0
5: Cloud & Streaming Friendly.Run PySpark on:.☁️ Databricks.⚙️ EMR.💠 Azure Synapse.🔥 Google Dataproc.And stream via Kafka, process via Delta, Iceberg, Hudi!.#CloudAnalytics #PySparkStreaming #ApacheKafka #DeltaLake.
0
0
0
4: Flexible ETL & Workflow Integration.Schedule PySpark ETL with:.🌀 Airflow.💧 NiFi.🚦 Oozie.🧱 dbt.🚀 KubeFlow Pipelines.Ideal for enterprise-grade orchestration!.#ETLTools #WorkflowAutomation #DataOps #PySparkETL.
1
0
0
3: Compatible with Your Favorite Notebooks.Develop with PySpark in:.📓 Jupyter.🧪 Databricks.🧠 Zeppelin.🎯 VS Code.✅ Even Google Colab (with setup).#PySparkDev #Notebooks #Jupyter #Databricks.
1
0
0
2: Machine Learning Made Easy.Use MLlib, integrate scikit-learn, XGBoost, or connect PyTorch & TensorFlow models. PySpark powers ML pipelines at scale. #MLlib #PySparkML #AI #DataScience.
1
0
0
1: PySpark Meets Data Lakes & Warehouses.PySpark integrates with top storage engines like HDFS, Hive, Cassandra, Delta Lake, and all major cloud storages (S3, GCS, Azure Blob). Scalable & storage-agnostic!.#PySpark #BigData #DataLakes #CloudStorage.
1
0
0
Tools supported by PySpark. A thread. ⬇️. #PySpark #BigData #DataLakes #CloudStorage #MLlib #PySparkML #AI #DataScience #PySparkDev #Notebooks #Databricks #ETLTools #WorkflowAutomation #DataOps #CloudAnalytics #ApacheKafka #DeltaLake

1
0
0
5: Enterprise Ready.PySpark is trusted by top enterprises for high-volume data workloads in production. It’s scalable, fault-tolerant, and battle-tested for modern data platforms. #EnterpriseAI #CloudDataEngineering #PySparkAtScale.
0
0
0
4: Seamless Integration.Use familiar Python libraries (Pandas, NumPy, scikit-learn) with Spark’s scalability. Connect to HDFS, Hive, Cassandra, AWS S3, and more. #PythonDataScience #CloudAnalytics #DataOps.
1
0
0