
Alexandre TL
@AlexandreTL2
Followers
743
Following
42K
Media
188
Statuses
516
Intern at @LinguaCustodia in Paris. (Pre|post)-training LLMs
Montpellier, France
Joined January 2020
muP works great for Mamba !.Zero-shot transfered the learning rate from a 172k model to a 105 model. Now part of 👇🧵

2
8
69
RT @SeunghyunSEO7: btw, i wrote a post about "how to scale" based on what i've learned over the past few months. it covers muP, HP scaling….
0
79
0



UPDATE.obv this run is too short to come to any conclusions


0
0
5
(because I replaced both these part with the Finewebedu data pipeline that matches the left version but not the right, you see how that caused problems).
0
0
2
Ok so I think I found what's going on. left is regular nanoGPT, right is JoeLi12345/nGPT. this is a veeery subtle change, that made the gpt/ngpt tried to predict the n+2th token in my runs. relaunching the 2 runs


1
0
4
Logs : Modified Nous nGPT : Modified nanoGPT : I really dont know what happened in their codebase. Please prove me wrong !.
0
0
10
The legend is as follows :.-nanogpt : taken straight from karpathy/nanoGPT, I just swapped the data part and put the one from modded-nanogpt.-ngpt_nous : again, straight from JoeLi12345/nGPT, just the data part that was changed.-gpt_nous : same, except that this is their regular.
1
0
7
The setup is the following, *for all the runs* in the graph : FineWebEdu, 5B tokens.124M/170M (depends if tied embeddings or not).lr : 30e-4.context size : 4096. batch size : 524k tokens. 10k steps. AdamW.
2
0
9
Got the chance to test out the nGPT implementation of @NousResearch but unfortunately their baseline (and their nGPT) is far behind nanoGPT, let alone modded-nanoGPT (11/08/24 record so very old, before Muon and stuff)

5
4
55
+link to the kernel (not that hard to read actually if you focus on the compute and IO parts, the beauty of TK).

0
0
5
that's it, hope that I will be able to post more about this stuff, this is really interesting!.@bfspector @simran_s_arora @AaryanSinghal4.
1
0
4
(but in TTT/Titans these chunks are also batches in the context of mini-batch gradient descent).
1
0
2
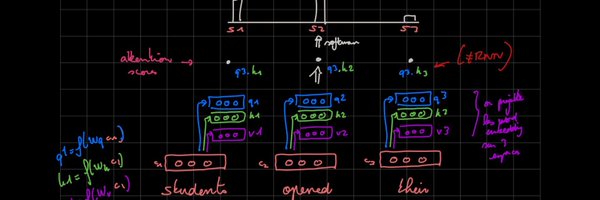
this is close to the TTT-Linear computation :.(not surprisingly because these architectures are different expressions of the same underlying thing)

1
0
3
if we received a new chunk of sequence (Q5, K5, V5), we would have : O5 = Q5 @ S + causal(Q5@K5^T) @ V.
1
0
3
hence the mask has no effect, we get back our associativity and we can factor out by Q4. we see appear what is usually denoted as S, and referred to as the memory. we can accumulate the K^T.V's in it.
1
0
4
BUT, in this big LxL matrix, parts of it are fully inside the causal mask and hence the causal mask has no effect. let's split our input in 4 chunks, like shown here. if we look at how the last output chunk O4 is computed, it is a sum of 4 QKV, with 3 fully inside the mask

1
0
5
so we get rid of softmax, and then what?.at first glance, that would enable us to compute K^TV then multiply by Q with associativity (line 2). no more L^2 FLOPs, right ?.in reality, the causal mask prevents us to do that and break the associativity (just like softmax did)

1
0
3