
Deep neural networks are just Gaussian Processes with a squared exponential kernel confirmed 😎
13
92
923
Replies
In all seriousness though, it wouldn't surprise me if this result could be shown to follow by modeling NNs as approximating a high dimensional Gaussian Process posterior! Especially given all the work on infinite width NNs being the same as GPs.

New paper!! We found a pattern in how NNs extrapolate: as inputs become more OOD, model outputs tend to go towards some “average”-like prediction.
What is this “average”-like prediction? Why does this happen? Can we leverage this to better handle OOD inputs? (Spoiler: Yes!)
🧵:

21
187
1K
1
3
45
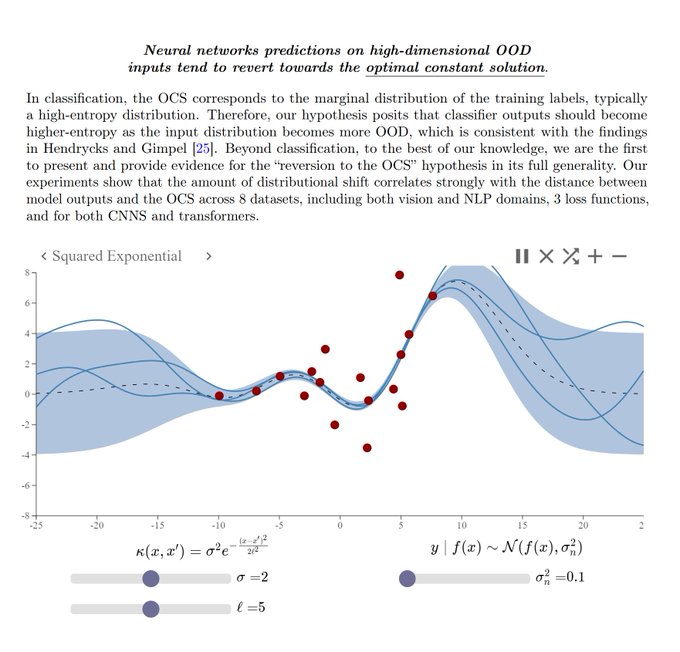
I feel like I should point out that my GP to the screenshot doesn't actually show reversion to the OCS ---- the mean of the GP is 0, but not the mean of the training data. To get reversion to the OCS, you have to explicitly fit the GP mean (which is a common preprocessing step).
0
0
7






@xuanalogue
So it turns out that deep neural networks are essentially Gaussian Processes, cloaked in a squared exponential kernel. Quite the revelation! 😎
0
0
1

@xuanalogue
Somehow not surprising observation from the Bayesian lens? In extrapolation areas, the (posterior) predictive distribution collapses to the "prior predictive distribution", which does not favor any particular class (OCS?).
0
0
1

@xuanalogue
Of course, wouldn't each neural net you train then count as one sample from the Gaussian process prior that's been evolved towards the marginal likelihood by training?
So you can't be very Bayesian with it.
0
0
1


@xuanalogue
Why the squared exponential kernel, specifically? Seems like it should vary with the choice of activations, loss function, and others.
0
0
0


