

Richard Diehl Martinez
@richarddm1
Followers
152
Following
55
Media
5
Statuses
59
CS PhD at University of Cambridge. Previously Applied Scientist @Amazon, MS/BS @Stanford.
Joined December 2009
Introducing Pico: a lightweight framework for language model learning dynamics
0
2
14
RT @piercefreeman: Text diffusion models might be the most unintuitive architecture around. Like: let's start randomly filling in words in….
0
3
0
RT @GeoffreyAngus: Struggling with context management? Wish you could just stick it all in your model?. We’ve integrated Cartridges, a new….
0
11
0
was making this fig showing amount training data for different models. Thought it kind of looked like those charts comparing size of sun to earth u see in school. Turns out diff between llama 3 and human is same ord. of magnitude as size of sun to earth.
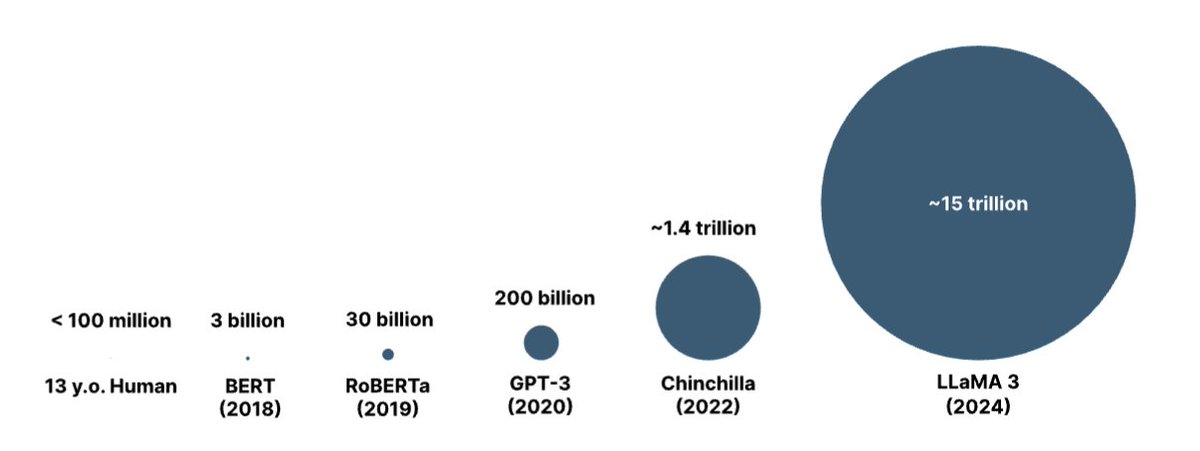
0
1
6
HF Trainer is especially brutal - it always takes me 10+ minutes to do the detective work of figuring out in which callbackhandler the call to wandb run.log() happens.
0
0
1
The pythonic way Trainer classes for language models are written is often a bad UX experience imo. There should be some benchmark that just times how long it takes users to find where the call to optimizer.step() occurs.
2
0
2
in case ur writing an nlp thesis rn - here's a pretty chunky bib I made that might be useful .
github.com
My Cambridge PhD Thesis (2025) . Contribute to rdiehlmartinez/phd-thesis development by creating an account on GitHub.
0
0
2
rlhf paper was arXived same day attention is all u need . wild cause in 2017 we def covered vaswani et al. in CS224N but no one talked about rlhf in CS234.
2
1
14
little insight - say u 2x ur batch size, well according to theory ur supposed to increase the lr by sqrt(2). why? because the std. dev of ur gradient estimates decreases by sqrt(2). Bascailly scaling lr by sqrt(2) is a way of keeping the signal to noise ratio the same.
0
0
2
you can just rm a file but if you want to delete a directory you better be -fr no cap.
0
0
5
Pico lets you apply the scientific method to language model development: You can quickly setup a small language model, train it, evaluate its learning dynamics and iterate.
1
1
5
Training language models is an art not a science. But I don't think it should be. That's why I've been working on ~Pico~ : .
www.youtube.com
Introducing PicoLM: A Modular Framework for Hypothesis-Driven Small Language Model ResearchFor more information visit: https://www.picolm.ioSupported by a gr...
1
1
12

Small language models are worse than large models because they have less parameters . duh! . Well not so fast. In a recent #EMNLP2024 paper, we find that small models have WAY less stable learning trajectories which leads them to underperform.📉 .
arxiv.org
Increasing the number of parameters in language models is a common strategy to enhance their performance. However, smaller language models remain valuable due to their lower operational costs....
0
5
17
We present 1) a method that improves performance on rare words 2) a metric for measuring how much a model prefers frequent vs. rare words.
0
0
1
Language Models tend to perform poorly on rare words - this is a big problem for niche domains!. Our Syntactic Smoothing paper (#EMNLP2024) provides a solution 👀.
arxiv.org
Language models strongly rely on frequency information because they maximize the likelihood of tokens during pre-training. As a consequence, language models tend to not generalize well to tokens...
2
3
25
RT @pietro_lesci: 🙋♂️My Lab mates are @emnlpmeeting this week: drop by their posters! . If you want to know more about our recent work [1]….
arxiv.org
Increasing the number of parameters in language models is a common strategy to enhance their performance. However, smaller language models remain valuable due to their lower operational costs....
0
5
0