Explore tweets tagged as #Hyperparameter

📢 Save Time on Hyperparameter Tuning with Hyperband!. Hyperparameter search can easily eat up days of compute and leave you drowning in experiments. Enter Hyperband, a bandit-based early-stopping strategy that lets you:. 1️⃣ What It Is. A smart scheduler that tests many

0
1
12

Deep learning training is a mathematical dumpster fire. But it turns out that if you *fix* the math, everything kinda just works…fp8 training, hyperparameter transfer, training stability, and more. [1/n]

14
150
1K

Don't be lazy: CompleteP enables compute-efficient deep transformers. - Sets α = 1 (no residual scaling) and rescales LR, init, LayerNorm, bias, ε, and weight decay to retain training stability.- Enables true hyperparameter transfer across width and depth.- Prevents layers from

3
27
159

Here are some of the most widely used techniques for hyperparameter optimization. The table below highlights the pros and cons of each strategy, helping you better understand when to use each one. Hope you find it helpful! 😉 . #machinelearning #datascience #ML #MLModels

1
0
11

🚀 Excited to announce Hyperoptax, a library for parallel hyperparameter tuning in JAX. Implements Grid, Random, and Bayesian search in pure JAX so that you can rapidly search across parameter configurations in parallel ‖. 📦 pip install hyperoptax.
3
6
48

#LSPPDay49.Tried Keras Tuner for hyperparameter tuning, tested different optimizers, activations, hidden layers & neurons. The initial model was heavily overfitted, but after tuning, the overfitting significantly dropped. @lftechnology.#60DaysOfLearning2025 #LearningWithLeapfrog



0
0
4

Muon optimizer doesn’t consistently outpace AdamW in grokking. Finding by:. The expanded hyperparameter sweep, tweaking transformer embedding dimensions and batch sizes reveals that validation accuracy curves for both optimizers converge similarly after

1
2
19

The best reads in a long time on how to improve Multi-Turn Tool Use with Reinforcement Learning for the future of agents. Open-Source Code, Hyperparameter, success details, failure details! 👀. Success:.> RL (GRPO) improved multi-turn tool use for the Qwen2.5-7B-Instruct model by

9
37
209

Hyperparameter Tuning for Deep Learning. #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode .




0
2
3

⛔️ AI development is hitting the limits of classical compute, especially when it comes to tuning models, optimizing parameters, and scaling across huge datasets. Cido uses quantum annealing to accelerate the slowest parts of the pipeline: hyperparameter tuning, model selection,
14
6
52

🤖 Friday AI Fact: Hyperparameters!. A hyperparameter in AI is a parameter whose value is set before the learning process begins. Unlike model parameters, hyperparameters control how the learning happens, like the learning rate, number of layers or batch size. #ELOQUENCEAI

0
0
3

Day 48 of #100DaysOfCode .-> Today I learnt about Hyperparameter tuning in Keras.-> Then practiced it on PIMA Indians diabetes dataset.-> Got accuracy of 0.77 although I didn't preprocessed the data


0
0
2

【新記事公開!】.マテリアルズインフォマティクス(MI)入門④【Optunaによるベイズ最適化で実践するハイパーパラメータチューニング】. 機械学習モデルのハイパーパラメータで自動に最適化してみませんか?
0
2
8

🎉WoS #HighlyCited.🔖TPTM-HANN-GA: A Novel #Hyperparameter_Optimization Framework Integrating the #Taguchi_Method, an #Artificial_Neural_Network, and a #Genetic_Algorithm for the Precise Prediction of #Cardiovascular_Disease_Risk.👥by Chia-Ming Lin et al.🔗

0
0
0

This has become my favorite hyperparameter in GBDT-based models. Borrows fundamental statistical thinking to combat overfitting

0
0
3

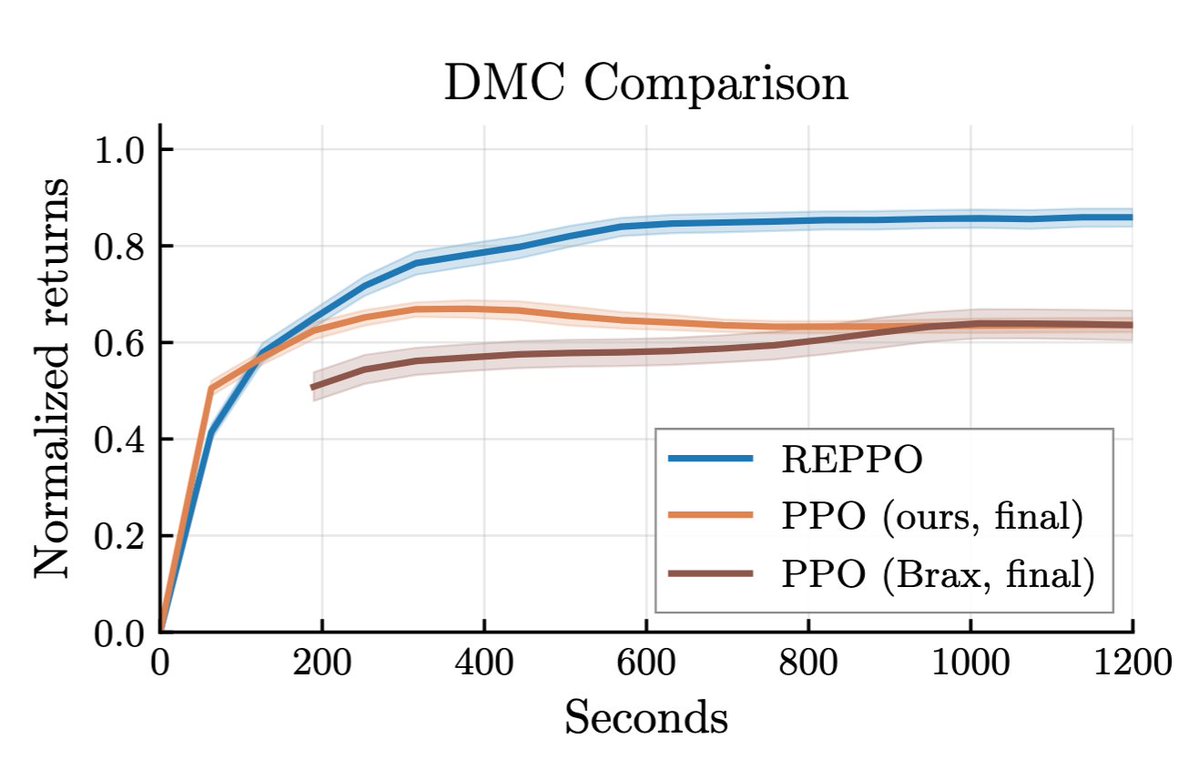
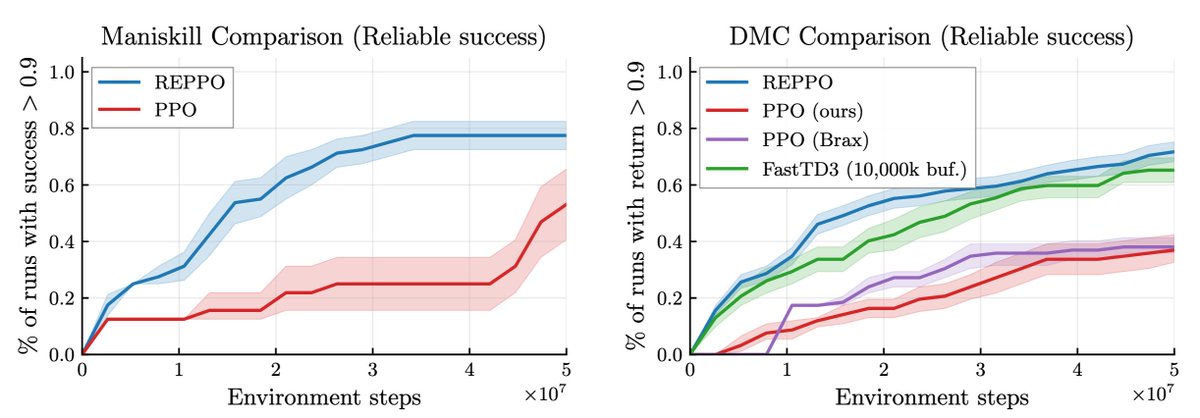
The result is REPPO, which trains as fast as PPO, without replay buffers, and with minimal hyperparameter tuning. If you don't believe us, take our code and test it! We provide implementations in both jax and torch (but jax is faster 😜):
1
0
6

Today I explored Optuna—an awesome framework for hyperparameter tuning!It uses Bayesian optimization to efficiently search for the best parameters. Smarter tuning, faster results. 🔍📊 #Optuna #MachineLearning #PyTorch




0
0
6

Cut Your Cloud Compute Costs by 10x - Join Our Funded Pilot Opportunity!. Are you a startup, researcher, or enterprise spending $5K+ per year on AWS, GCP, or Azure?.Do you run parallelizable AI workloads (like hyperparameter tuning, batch inference, KNNs, or ensemble methods)?

0
0
0
Grid Search 🆚 Random Search: Two powerful methods for hyperparameter tuning in Machine Learning. Here's a chart for a side-by-side comparison of their pros and cons. #DataScience #AI #ML #Machinelearning #hyperparameter #gridsearch #randomsearch

0
0
3