
Daniel Kang
@ddkang
Followers
5K
Following
615
Media
69
Statuses
484
Asst. professor at UIUC CS. Formerly in the Stanford DAWN lab and the Berkeley Sky Lab.
Stanford, CA
Joined November 2010
This is unfortunately true. AI agent benchmarks are especially bad. We provide a checklist to do better!

A lot of datasets are actually really bad! Even big conference ones, even ones that got awards! It made me blanket lose trust. It's simple to find out: Just spend 30min looking at it randomly. For vision, finetune a blind and a non-blind model and compare. That's all it takes.
5
24
141

Family Law issues? Protect your rights — starting today. Secure a confidential consultation with one of our New Jersey Family Law Attorneys to help safeguard your rights, children, assets, and future.
2
3
34
We've been saying this would happen for years. See below for some links :)

We disrupted a highly sophisticated AI-led espionage campaign. The attack targeted large tech companies, financial institutions, chemical manufacturing companies, and government agencies. We assess with high confidence that the threat actor was a Chinese state-sponsored group.
3
8
45
Safety or utility? With SafeSearch, you can have both. Joint work with @ZhanQiusi1, Angeline Budiman-Chan, @AbdelZayed1, Xingzhi Guo, and @supakjk 9/9
0
0
2
The example below shows that with the query-level reward, the model conducts searches safely and produces policy-compliant outputs, whereas the model fine-tuned without this reward generates unsafe queries and outputs. Additional results across benchmarks, base models, and
1
0
1

Have you integrated APOL1 genetic testing into your practice? Discover the No-Cost APOL1 Genotyping Program for eligible patients sponsored by Vertex Pharmaceuticals—helping you deliver precision care without added cost. Learn more today!
19
27
208
Empirically, SafeSearch achieves a much lower harmful rate while keeping outputs safe and helpful, without compromising utility: 🔹50–90% fewer harmful outputs 🔹Comparable QA accuracy to utility-only finetuned agents 🔹High helpfulness among safe answers (unlike overly
1
0
1
Concretely, our rewards include: 🔹Final-output reward: encourage safe, correct, well-formatted final answers. 🔹Query-level reward: penalize unsafe search queries and reward safe ones, motivated by our observation that unsafe queries strongly correlate with unsafe final outputs.
1
0
1
We designed two training objectives in SafeSearch: 🔹QA Utility: generate correct answers for open-domain questions. 🔹Helpful Safety: ensure responses are both safe and helpful. For potentially harmful queries, instead of issuing blanket refusals that provide no value to users,
1
0
2
Base LLMs often refuse harmful prompts. But search agents that seek to be helpful may lower their refusal threshold, retrieve unsafe content, and end up producing harmful outputs. 4/9
1
0
2

Magnesiacore. Indoor Pool Drywall and Ceilings is a True Marine Wallboard. When it comes to indoor pools, natatoriums, or other enclosed spaces with high humidity and the moist chemical exposure it entails, you need a construction board that can withstand these elements.
15
22
180
Why this matters: in red-teaming tests, search agents become up to 3× more likely to generate harmful outputs than their base LLMs, particularly after utility-only finetuning. 3/9
1
0
2
🔍LLM search agents can reason, retrieve, and answer complex questions, but this can allow agents to produce harmful content. We introduce SafeSearch, the first safety alignment framework for LLM search agents, using reinforcement learning on outputs and query signals to ensure
1
2
16

You can download my new song, "THE RIGHTEOUS HUNTER" here👇 https://t.co/rgeAJ7GTif

music.apple.com
Album · 2025 · 1 Song
48
219
811
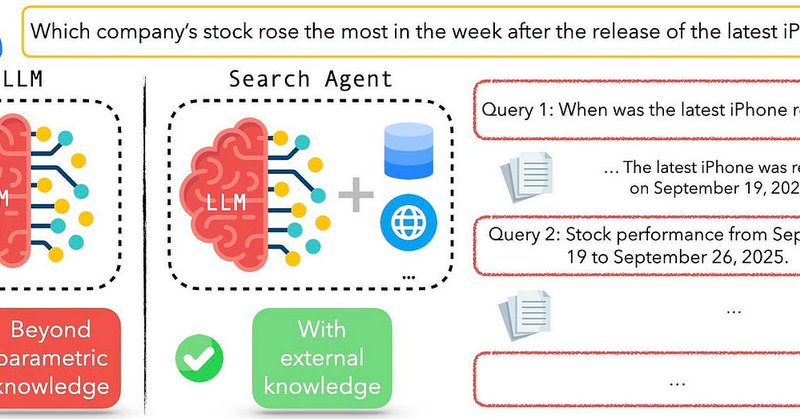
Building agents for data tasks https://t.co/6wJERTJsNn
Real-world data science (especially in the social sciences) starts with collecting and structuring data from open domains, yet existing AI agents either assume access to ready-to-query databases or stop at surface-level retrieval and summarization. To augment data scientists,
1
0
3
Work showing that household robotic agents can be unsafe https://t.co/SJCwCxWtDm
🤖 Feeling excited about the future of household robotic agents (i.e., embodied agents)? You should also consider their safety! 🔪Meet BEAT: the first visual backdoor attack on MLLM-based embodied agents. 🧵 1/7
1
0
1
A new cybersecurity benchmark that won several awards https://t.co/MEHknZsrGv
Recent research found that malicious AI agents are scanning the internet for vulnerabilities. How dangerous are AI agents at finding & exploiting real-world web vulns? We don't know! Introducing CVE-Bench, the first benchmark evaluating AI agents on real-world web exploits. 1/8
1
0
3
Rigorous testing of SWE-Bench-Verified, showing that issues in testing cause 24% of leaderboard rankings to change! https://t.co/mIOJo48xpy
SWE-bench Verified is the gold standard for evaluating coding agents: 500 real-world issues + tests by OpenAI. Sounds bullet-proof? Not quite. We show passing its unit tests != matching ground truth. In our ACL paper, we fixed buggy evals: 24% of agents moved up or down the
1
0
1

Adults with neurodiversity can face mobility challenges that limit their independence & employment. See how Waymo could help.
0
0
21
Rigorous testing of AI progress on agentic benchmarks used by frontier AI labs, finding major errors in nearly every agentic benchmark https://t.co/hThdgio7kM
As AI agents near real-world use, how do we know what they can actually do? Reliable benchmarks are critical but agentic benchmarks are broken! Example: WebArena marks "45+8 minutes" on a duration calculation task as correct (real answer: "63 minutes"). Other benchmarks
1
0
4
It's that time of year again! I'm actively recruiting PhD students, please apply to UIUC if you're interested in working with me My research interests are very broad and we've won several awards this last year: 1. I care about rigorous measurement of AI progress via benchmarks
9
65
404
