

Ruibo Liu
@RuiboLiu
Followers
3K
Following
2K
Media
23
Statuses
570
RS @GoogleDeepMind. AI Research with Humans in Mind.
Joined October 2015




this is huge. welcome! 🤗.

Big welcome to @_mohansolo and others from the Windsurf team joining Deepmind : ).
0
0
1
This is the coolest demo I have seen recently!. Now you can do: S_t -> A_t -> S_t+1, R_t . infinitely!. The real world model! 😇.

Hello Gemini 2.5 Flash-Lite! So fast, it codes *each screen* on the fly (Neural OS concept 👇). The frontier isn't always about large models and beating benchmarks. In this case, a super fast & good model can unlock drastic use cases. Read more:
0
1
5
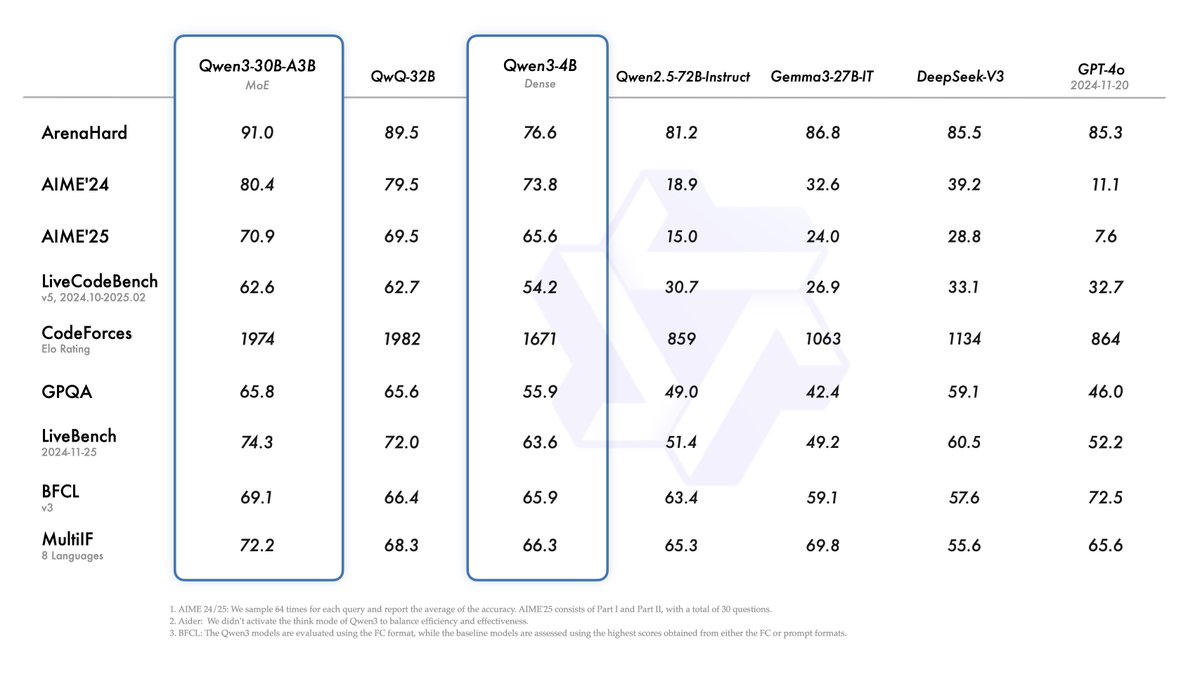
Very nice work! Congrats, Qwen team! 🥳. And glad to see the comparison includes Gemini 2.5 Pro --- the "best model in the world" in my opinion (yes, even after seeing some new models released these days). More to come. 😊.

Introducing Qwen3! . We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general

1
6
121
No confusing names, no $200/month. Strong, fast, and very affordable. Enjoy! 😉.

⚡ The latest Gemini 2.5 Flash has arrived on the leaderboard! Ranked jointly at #2 and matching top models such as GPT 4.5 Preview & Grok-3! Highlights:. 🏆 tied #1 in Hard Prompts, Coding, and Longer Query.💠 Top 4 across all categories.💵 5-10x cheaper than Gemini-2.5-Pro

1
8
153
Frontiers truly arrive when it is affordable and accessible to everyone! 🥳.

The pricing for 2.5 Pro is out. Here is the pareto performance of price : lmsys elo visualized as a rainbow.

0
0
6
Best of luck, bro! Hope our paths will cross again! 😘.

After an amazing journey at Google—first with Google Brain, then Google DeepMind—I’ve made the tough decision to leave. Immensely grateful for the brilliant colleagues and lifelong friends I’ve made along the way. I'm excited to keep riding the AI wave, creating stories that will

0
0
10
Apr 20, 2023 is the date when Brain and Deepmind merged. now it's about two years later. very happy to see the team achieved so much!. time flies.
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever (+40 pts vs Grok-3/GPT-4.5)! 🏆. Tested under codename "nebula"🌌, Gemini 2.5 Pro ranked #1🥇 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer

2
0
41
Never settle. 🫡.

1/ Gemini 2.5 is here, and it’s our most intelligent AI model ever. Our first 2.5 model, Gemini 2.5 Pro Experimental is a state-of-the-art thinking model, leading in a wide range of benchmarks – with impressive improvements in enhanced reasoning and coding and now #1 on
0
0
2
Happy coding 😀.

More news is coming that Nebula on LMSYS Arena is actually a Google model, probably Google Gemini 2.0 Pro Thinking Model. It is too good at coding too, Looks like Google is making sure to nail coding. Can’t wait 🔥🔥. Thanks @AnalogPvt for the info.

0
1
2
Very exiting opportunity! Apply now👇.

My team at @GoogleDeepMind is hiring a Research Scientist/Engineer for automated AI research with hands-on experience & strong track record. LLM/AutoML/RL is a plus. Send CV: crazydonkey@google.com (yes, it's real :) ) Subject: "DeepMind Job Application". Let's build together!🚀

0
0
4
my mum tried DeepSeek and told me she loved it because it could generate beautiful literature-level Chinese. she has zero idea about which model is leading those AGI/HLE benchmarks, but she knows what model can best serve her needs in an easily accessible and affordable way.
7
15
153
NVDA will be the new AAPL in the AI era. We will buy desktop AI workstations maybe every year just like how we purchase iPhone / iPad / MacBook nowadays.
2
0
14
Very well said and I learned a lot as well. Kindness is even harder than smartness, sometimes.

This is the most gut-wrenching blog I've read, because it's so real and so close to heart. The author is no longer with us. I'm in tears. AI is not supposed to be 200B weights of stress and pain. It used to be a place of coffee-infused eureka moments, of exciting late-night arxiv

0
0
4
My biggest takeaway of 2024 is that several new scaling methods are starting to shine. For example, data scaling (crazy overtraining in Llama 3), test-time scaling (o1, o3), etc. Parameter scaling—training ever larger LMs—seems to have diminishing gains and low ROI. If you could.
1
2
32