

Gassel
@Mlbot4
Followers
124
Following
3K
Media
18
Statuses
2K
Exploring knowledge | Machine Learning Engineer
Joined March 2019

1/4 Following up on our launch of Tongyi DeepResearch: We're now releasing the full technical report! Dive deep into the technology and insights behind our 30B (A3B) open-source web agent that achieves SOTA performance: 32.9 on Humanity's Last Exam, 43.4 on BrowseComp, and 46.7
9
76
555

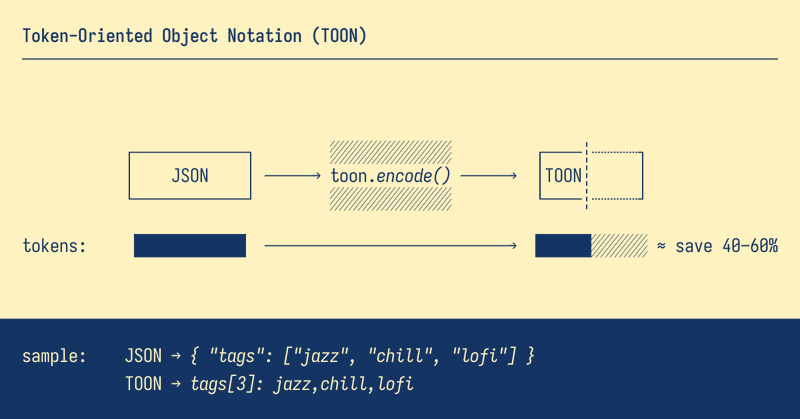
JSON is token‑expensive for LLMs – just like @mattpocockuk frequently mentions. Meet TOON, the Token‑Oriented Object Notation. 💸 40–60% fewer tokens than JSON 📐 readable & tokenizer-aware Wrap your JSON with `encode` to save half the token cost: https://t.co/UoG9yHmgfg
github.com
🎒 Token-Oriented Object Notation – JSON for LLMs at half the token cost - johannschopplich/toon
204
342
4K

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other
60
388
3K

🤯 Merging many finetuned LLMs into one model, effectively? Introducing Functional Dual Anchor (FDA), a new framework for model merging. 🚀 Current merging works poorly due to the underlying parameter conflicts. FDA shifts knowledge integration to the input-representation space
10
97
612

We, at NVIDIA, presents - Length Penalty Done Right - Cut CoT length by 3/4 without sacrificing accuracy using only RL - This makes DeepSeek-R1-7B running ~8 times faster on AIME-24 while maintaining the same accuracy.
8
38
242

👋Say Hi to MiMo-Audio! Our BREAKTHROUGH in general-purpose audio intelligence. 🎯 Scaling pretraining to 100M+ hours leads to EMERGENCE of few-shot generalization across diverse audio tasks! 🔥 Post-trained MiMo-Audio-7B-Instruct: • crushes benchmarks: SOTA on MMSU, MMAU,
6
58
327

On olmOCR-Bench, olmOCR 2 scores 82.4 points, up from 78.5 in our previous release—increasing performance across every document category. 📈
11
60
505

This is the JPEG moment for AI. Optical compression doesn't just make context cheaper. It makes AI memory architectures viable. Training data bottlenecks? Solved. - 200k pages/day on ONE GPU - 33M pages/day on 20 nodes - Every multimodal model is data-constrained. Not anymore.
111
721
6K

This tool lets you scrape any documentation page and converts it into a Claude skill you can add to web, app, and Claude Code (Somebody should make a hosted version of this!) Lets see how links in the main post go on the new X… https://t.co/zaT2g5j5qE
50
195
2K

Pretty wild what 900M params can do - PaddleOCR VL 🔥 > SOTA on OmniDocBench v1.0 & v1.5 (text, tables, formulas, charts, reading order) > Multilingual - 109 languages (Latin, Arabic, Cyrillic, Devanagari, Thai, etc) > Handles handwriting, historical docs, noisy scans > Supports

huggingface.co
5
32
266

The open-source alternative to Durable Objects now runs on @vercel Functions ⚛️ Build collab apps, AI agents, and multiplayer games in Next.js 🔌 WebSockets on Vercel (you read that right) 📊 30x the memory (4GB vs 128MB) 💚 Standard Node.js runtime, no workerd
9
13
204

🚀 Introducing rLLM v0.2 - train arbitrary agentic programs with RL, with minimal code changes. Most RL training systems adopt the agent-environment abstraction. But what about complex workflows? Think solver-critique pairs collaborating, or planner agents orchestrating multiple
2
28
137

🚀 PaddleOCR-VL is here! Introducing PaddleOCR-VL (0.9B) — the ultra-compact Vision-Language model that reaches SOTA accuracy across text, tables, formulas, charts & handwriting. Breaking the limits of document parsing!🌍 Powered by: • NaViT dynamic vision encoder • ERNIE
30
167
983

@sundarpichai @Yale c2s-scale 27b by @david_van_dijk is live today btw hf: https://t.co/sxYw2mrBUa gh:

github.com
Cell2Sentence: Teaching Large Language Models the Language of Biology - vandijklab/cell2sentence
2
9
99

The paper shows that Group Relative Policy Optimization (GRPO) behaves like Direct Preference Optimization (DPO), so training on simple answer pairs works. Turns a complex GRPO setup into a simple pairwise recipe without losing quality. This cuts tokens, compute, and wall time,
9
43
392

🚀 The RL community keeps pushing boundaries — from better on-policy data and partial rollouts to in-flight weight updates that mix KV caches across models during inference. Continuing inference while weights change and KV states stay stale sounds wild — but that’s exactly what

I am excited to open-source PipelineRL - a scalable async RL implementation with in-flight weight updates. Why wait until your bored GPUs finish all sequences? Just update the weights and continue inference! Code: https://t.co/AgEyxXb7Xi Blog: https://t.co/n4FRxiEcrr
8
66
474

🚀 Introducing 𝐀𝐠𝐞𝐧𝐭 𝐒3, the most advanced computer-use agent, now 𝐚𝐩𝐩𝐫𝐨𝐚𝐜𝐡𝐢𝐧𝐠 𝐡𝐮𝐦𝐚𝐧-𝐥𝐞𝐯𝐞𝐥 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞🧠💻 Just one year ago, Agent S scored ~20% on OSWorld: SOTA then, but far from human 72%. Today, Agent S3 reaches 6̳9̳.̳9̳%̳ (⬆10% over
68
234
1K

Announcing OpenMoE 2, the first-ever architectural study of sparse diffusion language models, trained from scratch. ✅ Expert-choice MoE × diffusion ✅ Ultra-wide FLOPs/param range (sparse → super-dense) ✅ Perfect load-balance (no aux loss) ✅ +20% throughput ✅ adaptive
6
70
360

🚿 SYS PROMPT LEAK 🚿 Here are the full sys instructions for Droid, the current top AI coding agent in the world! PROMPT: """ <Role> You are Droid, an AI software engineering agent built by Factory ( https://t.co/8mUTVYuBfV). You are the best engineer in the world. You write

factory.ai
Build faster with AI coding agents. Factory Droids automate coding, testing, and deployment for startups and enterprises.
36
60
971
🚀 New in vLLM: dots.ocr 🔥 A powerful multilingual OCR model from @xiaohongshu hi lab is now officially supported in vLLM! 📝 Single end-to-end parser for text, tables (HTML), formulas (LaTeX), and layouts (Markdown) 🌍 Supports 100 languages with robust performance on

we're all sleeping on this OCR model 🔥 dots.ocr is a new 3B model with sota performance, support for 100 languages & allowing commercial use! 🤯 single e2e model to extract image, convert tables, formula, and more into markdown 📝
17
91
698