

Matthew Walmer
@MatthewWalmer
Followers
32
Following
9
Media
6
Statuses
13
Computer Vision PhD student at University of Maryland College Park Website: https://t.co/7rfVPC9ZUS
Joined June 2022
RT @_sakshams_: We are happy to release our LiFT code and pretrained models! 📢. Code: Project Page: .
0
46
0
RT @_sakshams_: We introduce LiFT, an easy to train, lightweight, and efficient feature upsampler to get dense ViT features without the nee….
0
149
0
Just a reminder we’ll be presenting this evening at the Tuesday 4:30pm poster session at #CVPR2023. Hope to see you there!.
We’re looking forward to presenting our work “Teaching Matters: Investigating the Role of Supervision in Vision Transformers” next week at #CVPR2023! We’ll be in the Tues-PM poster session at board 321. Links and some key results below. @_sakshams_ @kamalgupta09 @abhi2610.[1/5]
0
0
1
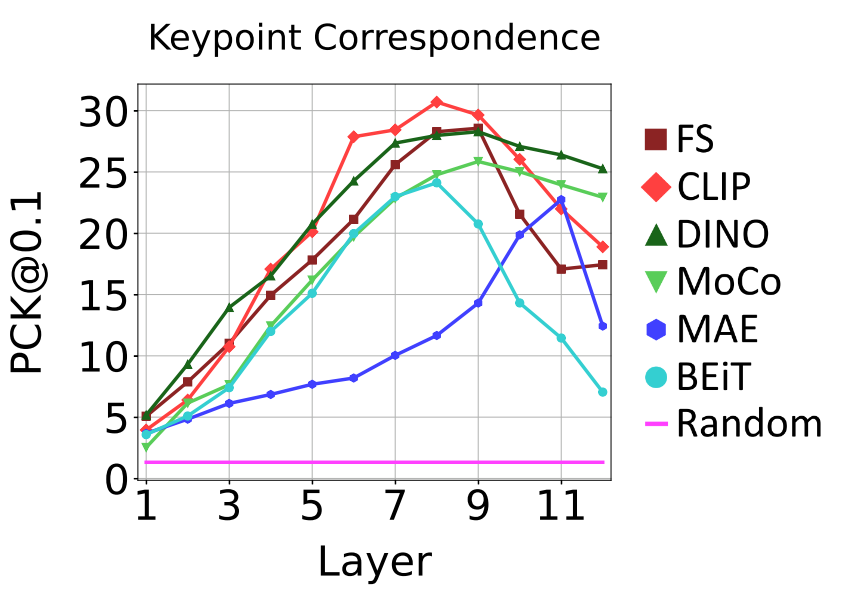
@_sakshams_ @kamalgupta09 @abhi2610 The best layer for a downstream task varies depending on both the task and the pretraining. For example, on keypoint correspondence, most of the ViTs have their best performance with layers 7 or 8 (of 12). We present comparisons for both locally and globally focused tasks. [5/5]
0
0
3
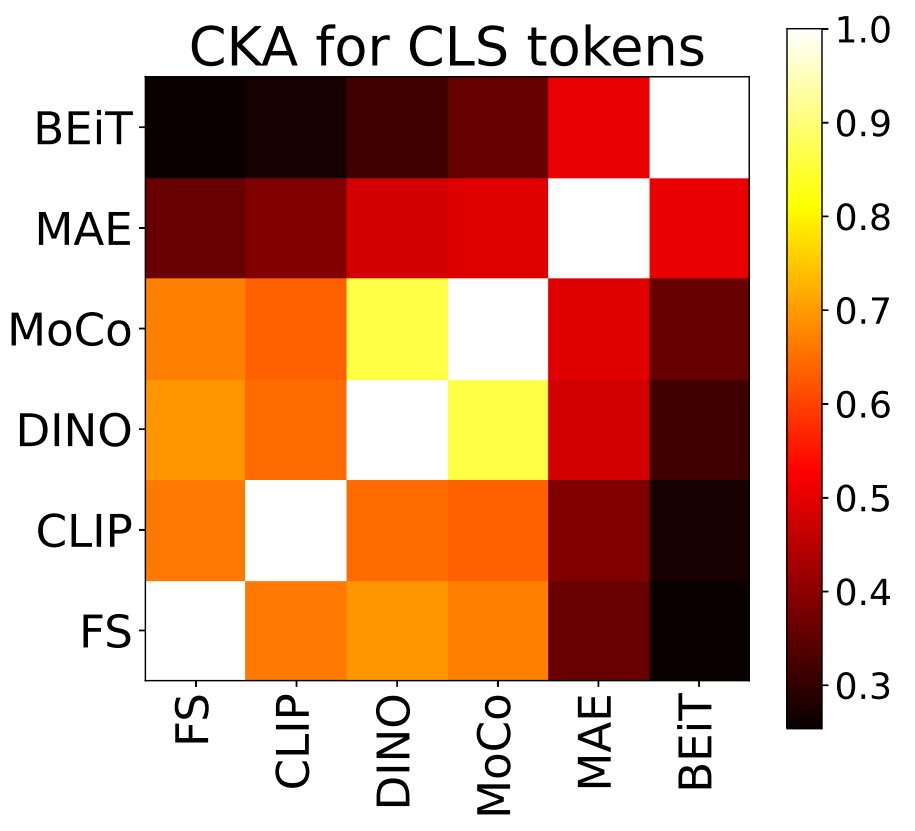
@_sakshams_ @kamalgupta09 @abhi2610 Even though MAE has no CLS objective, we find evidence that it learns to embed semantic information in the CLS token even before fine-tuning. Through CKA analysis, we find some similarity between MAE, DINO, and MoCo CLS token representations. [4/5]
0
0
3
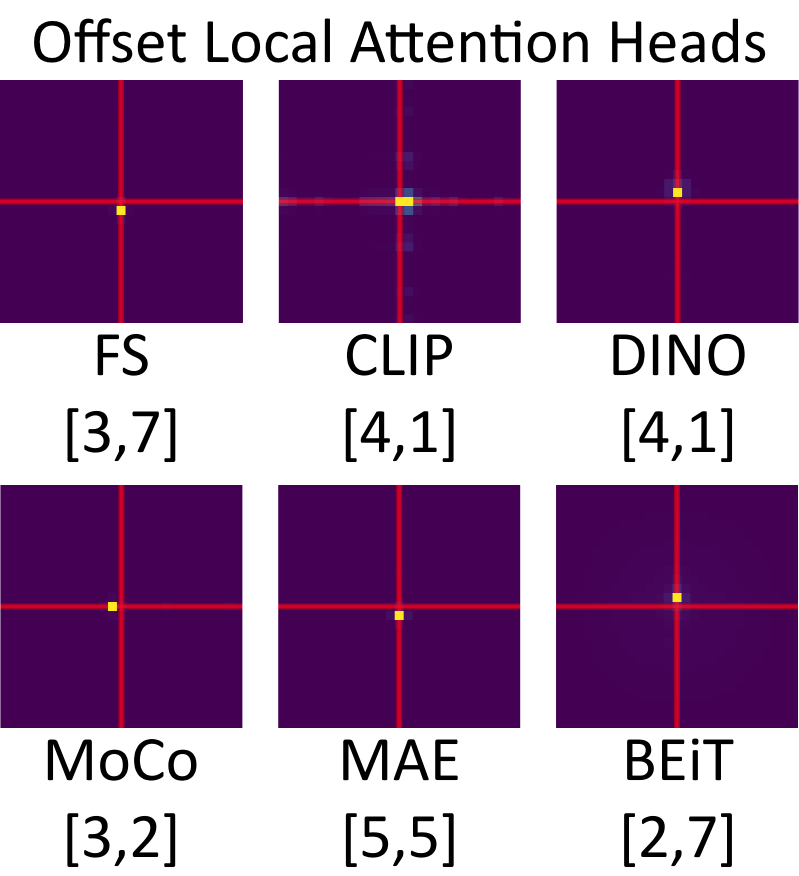
@_sakshams_ @kamalgupta09 @abhi2610 Did you know that ViTs learn to use offset local attention heads? These heads attend locally, but to a position that is one off in one direction. The existence of these heads may actually demonstrate a strength of CNNs over ViTs. [3/5]
0
0
3
@_sakshams_ @kamalgupta09 @abhi2610 We compared ViTs from 6 different supervision methods and identified key similarities and differences between them. We examine: attention, features, and downstream performance. Paper: Website: Code: [2/5]

0
0
3
We’re looking forward to presenting our work “Teaching Matters: Investigating the Role of Supervision in Vision Transformers” next week at #CVPR2023! We’ll be in the Tues-PM poster session at board 321. Links and some key results below. @_sakshams_ @kamalgupta09 @abhi2610.[1/5]
4
1
7
RT @_sakshams_: Excited to share our work "Teaching Matters: Investigating the Role of Supervision in Vision Transformers" which has been a….
0
8
0
RT @aerinykim: Before I forget, I'd like to summarize some interesting papers that I found at #CVPR2022. Dual-key multimodal backdoors for….
0
50
0
Today we’re presenting our poster for “Dual Key Multimodal Backdoors for Visual Question Answering” at #cvpr2022. Afternoon poster session, 201b. You can also test out some backdoored for yourself models with our demo:

0
10
25
Can you tell if a Neural Net contains a Backdoor Attack? Try this demo for "Dual-Key Multimodal Backdoors for Visual Question Answering" (CVPR 2022) created using Gradio @ksikka1 @SurIndranil @abhi2610 @susmitj @umdcs @umiacs @SRI_Intl @huggingface @Gradio.
0
7
20