
Gopala Anumanchipalli
@GopalaSpeech
Followers
1K
Following
1K
Media
3
Statuses
156
Robert E. And Beverly A. Brooks Assistant Professor @UCBerkeley @UCSF Formerly @CarnegieMellon @ISTecnico @IIIT_Hyderabad
Berkeley, CA
Joined May 2018
🧠 New preprint: How Do LLMs Use Their Depth? We uncover a “Guess-then-Refine” mechanism across layers - early layers predict high-frequency tokens as guesses; later layers refine them as context builds Paper - https://t.co/5PitHjmJJZ
@neuranna @GopalaSpeech @berkeley_ai
15
72
517
Just did a major revision to our paper on Lifelong Knowledge Editing!🔍 Key takeaway (+ our new title) - "Lifelong Knowledge Editing requires Better Regularization" Fixing this leads to consistent downstream performance! @tom_hartvigsen @_ahmedmalaa @GopalaSpeech @berkeley_ai
1
7
27
Excited to have two paper accepted at #ACL2025 !🎉🎉 1 Main track and 1 Findings. Papers out on arxiv soon. Big thank you to all my collaborators!
3
6
40

🚀 Excited to share that our paper on Plan-and-Act has been accepted to ICML 2025. Below is a TLDR: 🔎 Problem: • LLM agents struggle on complex, multi-step web tasks (or API calls for that matter). • Why not add planning for complex tasks and decouple planning and execution?
0
5
14
#ICLR25 Our work on characterizing alignment between MLP matrices in LLMs and Linear Associative Memories has been accepted for an Oral Presentation at the NFAM workshop. Location : Hall 4 #5 Time : 11 AM (April 27) @GopalaSpeech @berkeley_ai
0
1
5

Work led by BAIR students @KayloLittlejohn and @CheolJunCho advised by BAIR faculty @GopalaSpeech "...made it possible to synthesize brain signals into speech in close to real-time." https://t.co/JOwRq8KrDf via @dailycal

dailycal.org
A recent breakthrough has been made by UC Berkeley and UC San Francisco researchers in developing a brain-to-voice neuroprosthesis, which aids in restoring naturalistic speech to people with paraly...
0
7
21
This thread is an excellent and accurate summary of our work ! Thank you @IterIntellectus !

🚨IT'S HAPPENING🚨 a woman who cannot speak now speaks through her brain, in real time, with her own voice. no typing, delay, or sounds made. just neural intent to streaming speech this isn’t prediction. it’s embodiment 1/
1
0
9

Scientists have developed a device that can translate thoughts about speech into spoken words in real time. Although it’s still experimental, they hope the brain-computer interface could someday help give voice to those unable to speak.
21
64
207

A paper in @NatureNeuro presents a new device capable of translating speech activity in the brain into spoken words in real-time. This technology could help people with speech loss to regain their ability to communicate more fluently in real time. https://t.co/KfIb57KoDR
4
46
118

Today in @NatureNeuro, @ChangLabUCSF and @Cal_Engineer’s @GopalaSpeech show that their new AI-based method for decoding neural data synthesizes audible speech from neural data in real-time: https://t.co/kcBph7k02E
0
9
33

1/n) Our latest work is out today in @NatureNeuro! We developed a streaming “brain-to-voice” neuroprosthesis which restores naturalistic, fluent, intelligible speech to a person who has paralysis. https://t.co/EAk1Wz25TH
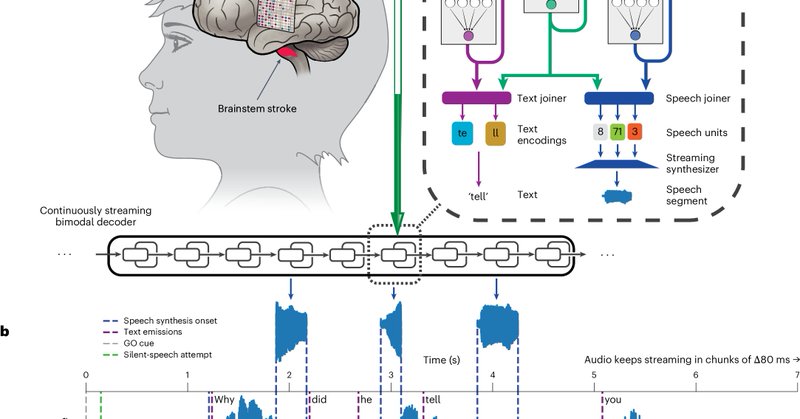
nature.com
Nature Neuroscience - Naturalistic communication is an aim for neuroprostheses. Here the authors present a neuroprosthesis that restores the voice of a paralyzed person simultaneously with their...
31
183
703

(1/5) Introducing Full-Duplex-Bench: A Benchmark for Full-Duplex Spoken Dialogue Models We’re excited to present Full-Duplex-Bench, the first benchmark designed to evaluate turn-taking capabilities in full-duplex spoken dialogue models (SDMs)! https://t.co/78eNKtMAqb Details👇
1
9
40
Our work on knowledge editing got an "Outstanding Paper Award"🏆🏆 at the @RealAAAI KnowFM Workshop!! #AAAI2025 🥳🥳🥳 Congratulations to my amazing co-authors @tom_hartvigsen @_ahmedmalaa @GopalaSpeech

Thrilled to share that our paper on "Norm Growth and Stability Challenges in Sequential Knowledge Editing" has been accepted for an Oral Presentation at the KnowFM workshop @ #AAAI2025 w/ @tom_hartvigsen @_ahmedmalaa @GopalaSpeech More details below (1/n)
1
6
45
Thrilled to share that our paper on "Norm Growth and Stability Challenges in Sequential Knowledge Editing" has been accepted for an Oral Presentation at the KnowFM workshop @ #AAAI2025 w/ @tom_hartvigsen @_ahmedmalaa @GopalaSpeech More details below (1/n)
2
4
16
Self-Supervised Syllabic Representation Learning from speech. With unsupervised syllable discovery & linear time tokenization of speech at the syllabic rate (~4 Hz) !! Work from my group Cheol Jun Cho, @nicholaszlee and @akshatgupta57 @berkeley_ai to be presented at #ICLR2025

``Sylber: Syllabic Embedding Representation of Speech from Raw Audio,'' Cheol Jun Cho, Nicholas Lee, Akshat Gupta, Dhruv Agarwal, Ethan Chen, Alan W Black, Gopala K. Anumanchipalli,
1
8
32

I will be attending #NeurIPS2024 presenting our work SSDM: Scalable Speech Dysfluency Modeling ( https://t.co/97IRz391Ki), East Exhibit Hall A-C #3207, on Thursday, December 12th, 4:30-7:30 PM PST. Hope to meet with old and new friends!
2
2
9
Please checkout the following works on LLM editing and characterization next week at #EMNLP2024
✈️ Heading to Miami for @emnlpmeeting ! Excited to present a few of our papers and connect with the amazing people at EMNLP. If you're attending, DM me and let's catch up and talk all things language models, knowledge editing, interpretability and more! #EMNLP2024 #NLP
0
0
3
``Sylber: Syllabic Embedding Representation of Speech from Raw Audio,'' Cheol Jun Cho, Nicholas Lee, Akshat Gupta, Dhruv Agarwal, Ethan Chen, Alan W Black, Gopala K. Anumanchipalli,
0
5
21
If you are at #SfN2024, check out our poster in section F9 from 8 AM to 12 PM on Sunday! We present a streamable framework to restore a naturalistic voice to a person with paralysis. We will also show demos of voice synthesis, incremental TTS, and generalization to unseen words.
0
1
16

Catch us at poster #242 on Thursday at 4:30 PM! More details here: 🔗 Website: https://t.co/IvqpqWVFX9 📄 arXiv: https://t.co/aKu3MSsxhg w/ @ren_wang1 , Bernie Huang, @andrewhowens , and @GopalaSpeech .

arxiv.org
Speech sounds convey a great deal of information about the scenes, resulting in a variety of effects ranging from reverberation to additional ambient sounds. In this paper, we manipulate input...
0
2
6